The core of the Beyond Planck project revolves around developing a single end-to-end analysis framework that converts raw bits from the Planck LFI instrument into final science products in the form of sky maps, cosmological parameters and astrophysical models. This overall machine may be implemented in terms of a Gibbs sampler, and is as such an intrinsically iterative approach.
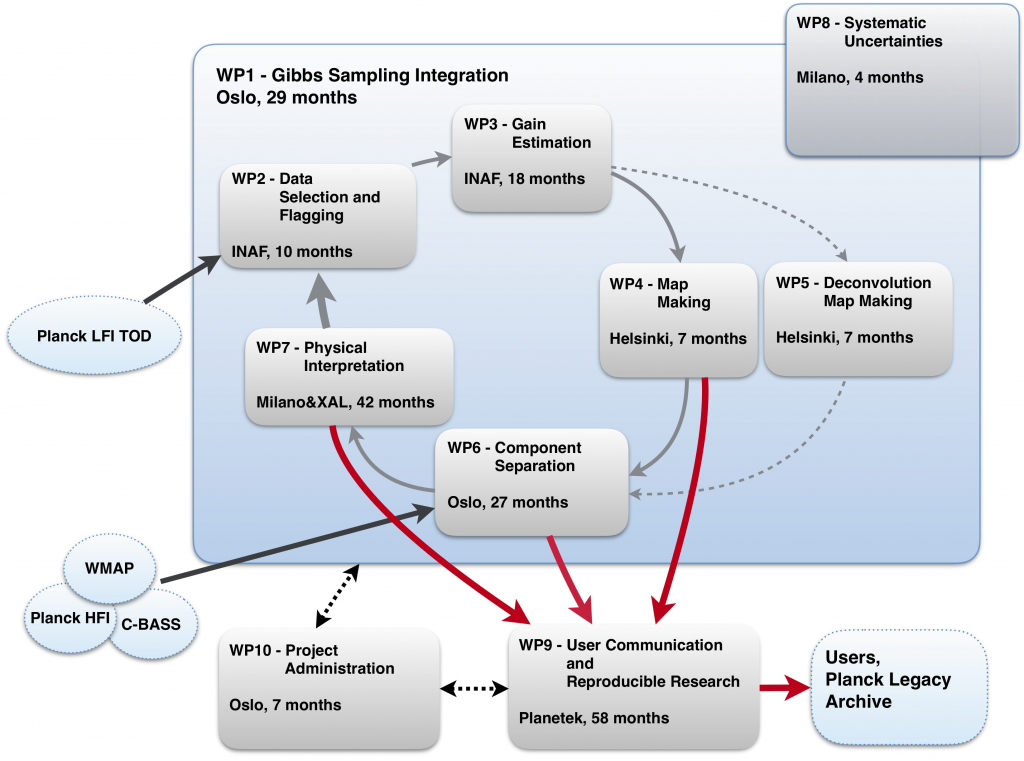
Schematic overview of work packages and their inter-dependencies. In this diagram 'Months' correspond to personmonths, not WP duration.
The work flow corresponding to this approach is schematically illustrated in the figure above in terms of WPs and their inter-relationships. Going through this diagram in chronological order, we start the process by inserting observations from Planck and external experiments (ellipses on the left-hand side) into the overall Gibbs sampler (WP1). The raw Planck LFI time-ordered data are first processed through a Data Selection module (WP2) that identifies and removes (ie., flags) any bad data segments from further processing. Note that this process can be made significantly more accurate and efficient by using prior information regarding what the sky actually does look like.
The second step in the processing is Gain Estimation (WP3), which translates measured voltages to astrophysically relevant sky temperatures. The main calibrators for this purpose are the Doppler-induced CMB dipole due to the Earth’s motion around the Sun, and the corresponding dipole due to the Sun’s motion with respect to the background. However, in order to reach the necessary sub-μK precision level required for this project, it is essential to also account for radiation from the Milky Way.
Having clean and calibrated data at hand, the third step is to produce clean frequency maps through Map Making (WP4 / WP5). This corresponds essentially to performing a weighted average for each sky pixel over all samples falling within that pixel. We will implement two different approaches for this purpose, namely standard destriping, as implemented in the state-of-the-art MADAM code (WP4), but also so-called beam-deconvolved map making (WP5). Since the instantanous instrumental response function, often called “point-spread function” or “beam”, of a CMB detector is generally azimuthally asymmetric, the measured output from the detector depends on the specific orientation of the detector with respect to the sky. This effect can, however, be accounted for by taking into account the known beam response profile and the detector orientation through so-called beam deconvolution. This approach results in maps with simpler signal properties than standard maps, but more complicated noise properties. As a result, the optimal method depends on the particular application the maps will be used for. We will implement both, but note that the standard destriper approach will be our main algorithm of choice.
The fourth step is Component Separation (WP6), and for this we will adopt the well-established Bayesian Commander framework discussed above. This WP will be responsible for deriving astrophysical component maps (CMB, synchrotron, free-free, spinning and thermal dust emission etc.) from the frequency maps, as well as combining the Planck LFI maps with external data, whether they come from WMAP, C-BASS, Planck HFI or any other source.
Fifth and finally, the analysis chain is completed by Physical Interpretation (WP7). This WP derives cosmological and astrophysical science from the component maps generated in WP6, and as such serves as the highest-level analysis step in the pipeline. Products from this WP includes, but are not limited to, angular CMB power spectra and cosmological parameters.
So far, the analysis pipeline outlined above follows a very conventional procedure, with a linear progression from raw data to final science products. However, the fundamentally new step in our procedure is to close the loop, indicated by a bold arrow from WP7 back to WP1, indicating that this will indeed by a circular and iterative process, as opposed to the standard one-shot linear process. The main task of WP1 (Gibbs sampling) is to provide the computational infrastructure that binds this entire process together.
In addition to the main Gibbs-related WPs, we also define two external special-purpose WPs. The first of these is called Systematic Errors (WP8), which carries the responsibility of understanding and quantifying residual systematic errors in the final data products after full processing. This work will partly take place inside the main infrastructure and partly outside. Generally speaking, this work will revolve around understanding the behaviour of the instrument in light of the most up-todate models, and determine how and why they differ. Thus, the typical mode of operation will be to establish an imperfect model of a given instrumental effect; project this into time-ordered data; process those data through the pipeline; and quantify the residuals.
The ninth WP is called User communication and reproducible research (WP9), and is responsible for all aspects of user communication. We adopt an ambitious philosophy based on reproducible research concepts, ensuring that all deliveries are well understood, documented and accessible by external users. This work package is responsible also for delivery of all products to external repositories, including to the Planck Legacy Archive.
Finally, the 10th and last WP covers all administrative and non-scientific aspects of the project, including budgeting, audits, meeting organization etc.